Text Embeddings Overview
From words to documents
- Word embeddings: Individual words → vectors
- Document embeddings: Entire documents → vectors
- Context-aware: Meaning depends on surrounding text
Word Embeddings
Individual words as vectors
- Word2Vec: Predicts words from context
- GloVe: Global word-word co-occurrence statistics
- FastText: Handles out-of-vocabulary words
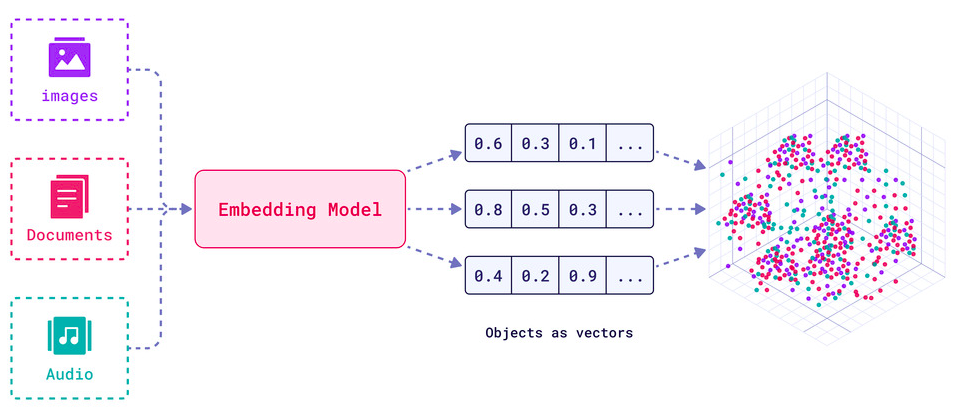
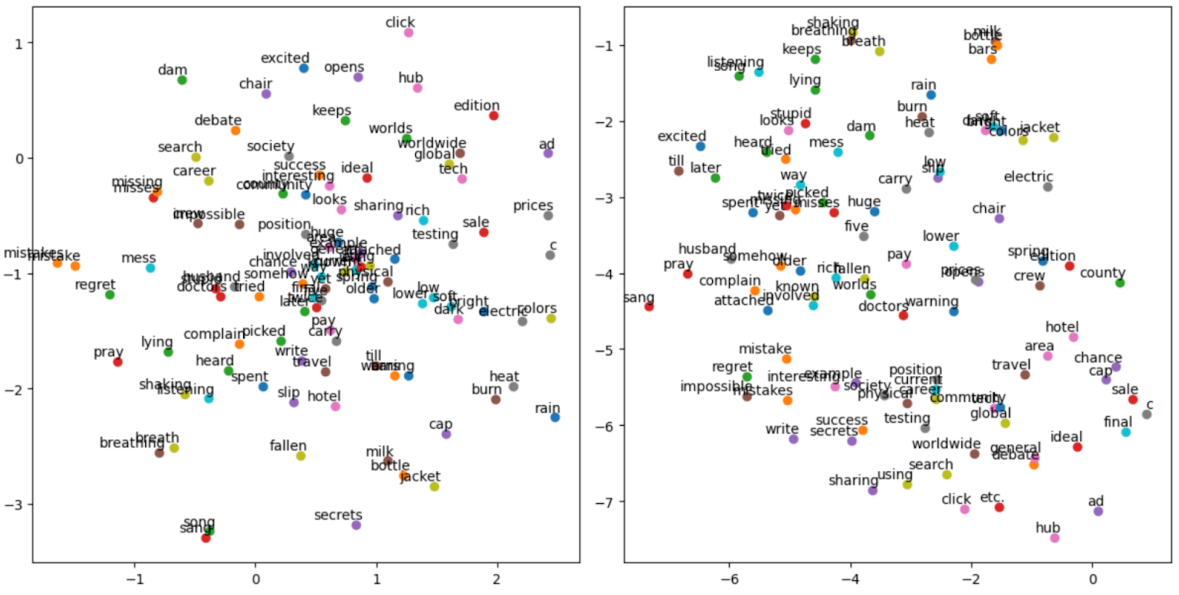
![]()
Word embeddings showing similar words clustered together in vector space
Document Embeddings: Shallow Models
Bag-of-words approaches
- TF-IDF: Term frequency × inverse document frequency
- BM25: Probabilistic ranking function
- Limitations: No word order, no context
Document Embeddings: Deep Models
Context-aware neural embeddings
- BERT: Bidirectional encoder representations
- Sentence-BERT: Efficient sentence embeddings
- Modern LLMs: GPT, T5, Gemini embeddings
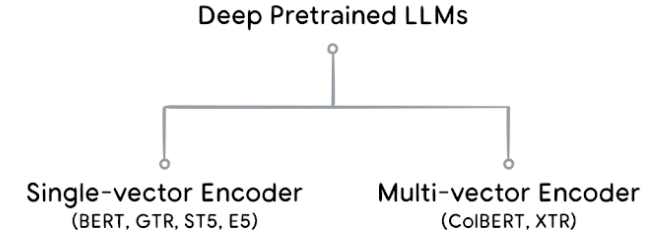
![]()
Single-vector vs. Multi-vector encoders
Image & Multimodal Embeddings
Visual understanding in vector space
- CNN-based: Convolutional neural networks for images
- Vision transformers: ViT, CLIP for joint text-image space
- Multimodal: Same space for text, images, videos
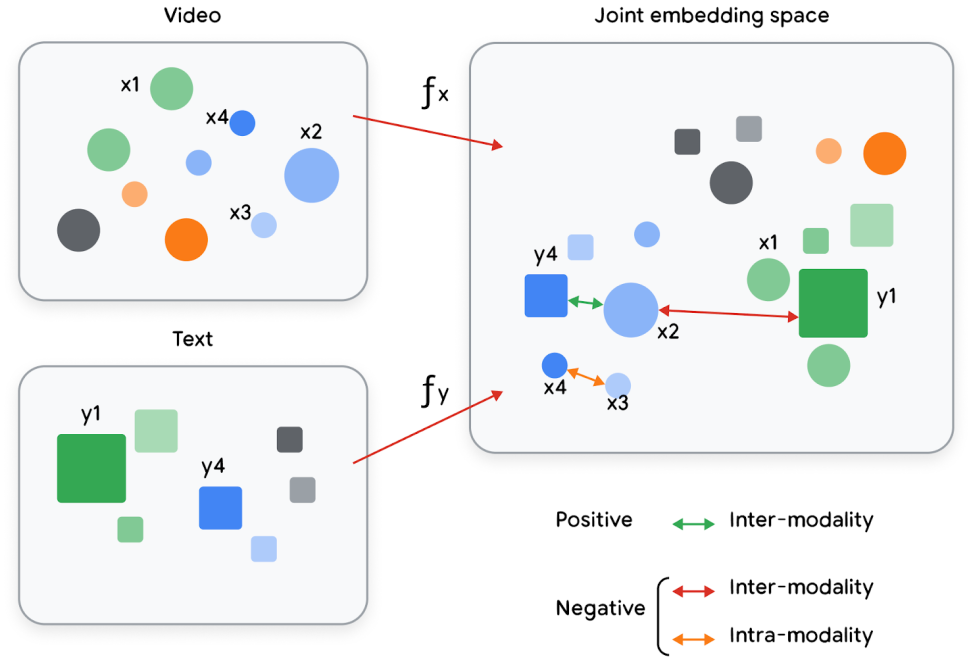
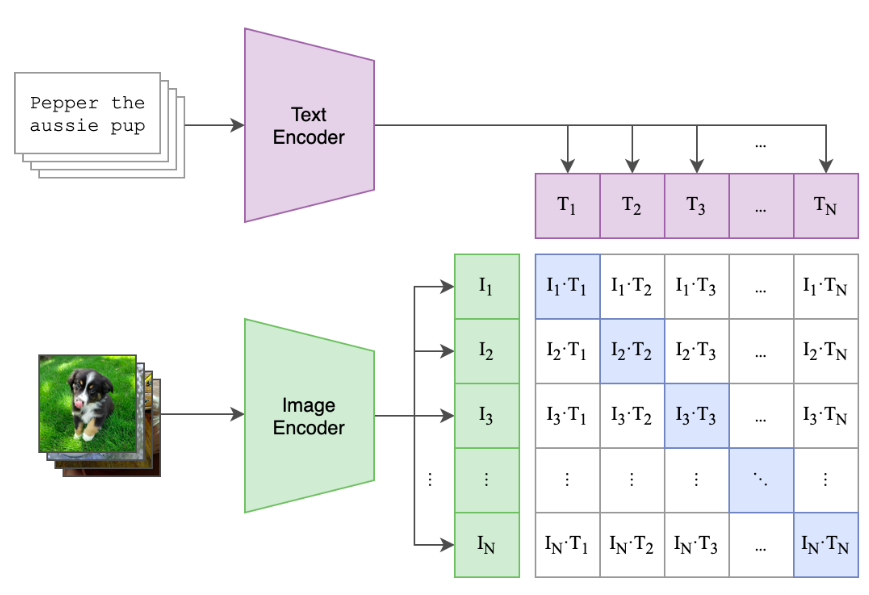
![]()
Images and text projected into a joint embedding matrix (OpenAI’s CLIP model)
Structured Data Embeddings
Tables, graphs, and relational data
- General structured data: Feature engineering + ML
- User-item data: Collaborative filtering embeddings
- Graph embeddings: Node and edge representations