مقدمة عن تعلم الآلة
المبادئ العشرة
إنَّ مبادئ كل فن عشرة … الحد والموضوع ثم الثمرة
وفضله ونسبة والواضع … والاسم الاستمداد حكم الشارع
فمسائل والبعض بالبعض اكتفى … ومن درى الجميع حاز الشرفا
1. الـحَدُّ (التعريف)
- علم يبحث في قدرة المنطق الآلي على استخراج الأنماط المفيدة من البيانات تلقائيًّا.
- توم ميتشيل: البرنامج يتعلم من الخبرة (\(E\)) للمهام (\(T\)) بمقياس (\(P\))، إذا تحسن الأداء في (\(T\)) بقياس (\(P\)) مع زيادة (\(E\)).
2. المَوْضُوع
- البيانات (Data)
- الأنماط (Patterns)
- العلاقة بين المدخلات (\(X\)) والمخرجات (\(Y\))
3. الـثَّمَرَة
- أتمتة الاستدلال
- التعميم (Generalization)
- حل المشكلات المعقدة (الرؤية، الكلام، التفاعل)
4. الـفَضْل
- محرك الثورة التقنية الحالية.
- استعصاء المهمة على الصياغة الإجرائية.
- الحاجة للتكيف المستمر.
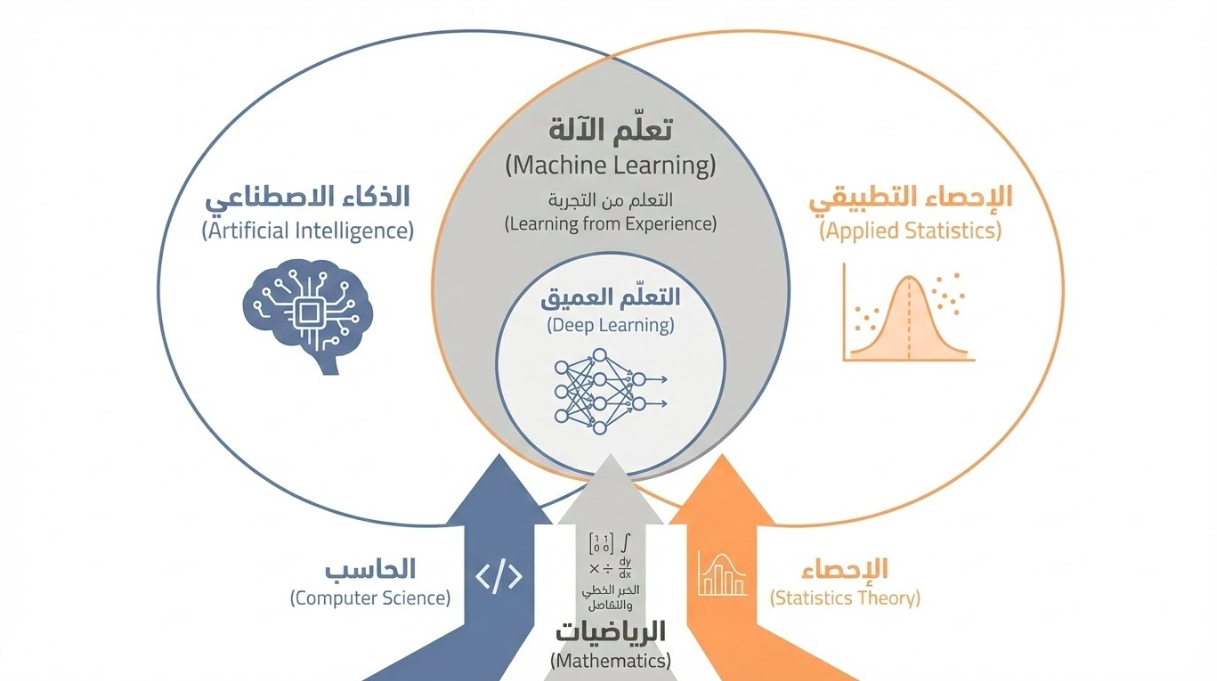
5. الـنِّسْبَة
- للذكاء الاصطناعي: جزء من كل.
- للإحصاء: تداخل عميق (التعلم الإحصائي).
- للتعلّم العميق: فرع (شبكات عصبية).
6. الاسْـتِمْدَادُ
- الرياضيات (جبر خطي، تفاضل، تحسين)
- الإحصاء والاحتمالات
- علوم الحاسب (خوارزميات)
7. الـوَاضِع
تراكم معرفي وليس شخصًا واحدًا:
- التأسيس (1950): اختبار تورينج.
- المنطق (1956): الأنظمة الخبيرة.
- البيانات (1990s): الإحصاء وتعلم الآلة.
8. الاسْم
- تعلم الآلة (Machine Learning)
- التعلم الإحصائي (Statistical Learning) (أكاديميًا)
- استخراج الأنماط / التنقيب في البيانات
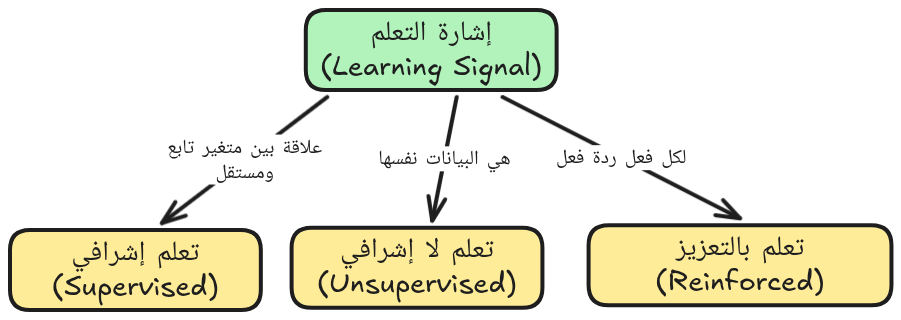
9. المَـسَائِل
ثلاثة أقسام حسب إشارة التعلم:
- التعلم الإشرافي (Supervised)
- التعلم اللا إشرافي (Unsupervised)
- التعلم بالتعزيز (Reinforcement)
القسم الأول: التعلم الإشرافي
- البيانات موسومَة (Labeled)
- أمثلة:
- حالة الطقس
- تنظيم النشر
- تصنيف الصور

القسم الثاني: التعلم اللا إشرافي
- لا يوجد وَسم صريح.
- كشف النمط الكامن / التكتل.
- أمثلة:
- محركات البحث
- التحليل التسويقي
- مشابهة الصور

القسم الثالث: التعلم التعزيزي
- التفاعل مع البيئة (ثواب/عقاب).
- أمثلة:
- أنظمة التوصية
- الألعاب المعقدة
- الروبوتات

مثال: الترجمة بالقواعد الإجرائية
- يتطلب المبرمج كتابة كل قاعدة يدوياً.
- “إذا حدث هذا، افعل ذاك”.
- صعب التعامل مع الاستثناءات.
الترجمة بالقواميس والقواعد اللغوية
في هذا النموذج، يقوم المبرمج بدور اللغوي. حيث يجب عليه كتابة كل قاعدة نحوية وكل مفردة يدوياً. إذا لم تكن القاعدة مكتوبة في الكود، فلن يفهمها النظام.
def rule_based_translate(sentence):
# Dictionary (Lexicon)
dictionary = {
"the": "el",
"cat": "gato",
"is": "está",
"black": "negro",
"house": "casa"
# ...
}
words = sentence.lower().split()
translated = []
for i, word in enumerate(words):
# Rule 1: Direct word-for-word mapping
trans_word = dictionary.get(word, word)
# Rule 2: Spanish Adjective Placement
# (e.g., "black cat" -> "gato negro")
if word == "black" and i > 0 and words[i-1] == "cat":
# Swap previous word with current translation
# ...
pass
else:
# ...
pass
# Rule 3: ...
# Rule 4: ...
return " ".join(translated)
print(rule_based_translate("the black cat"))
# Output: el gato negroيتطلب هذا النوع جهداً بشرياً هائلاً لصياغة آلاف القواعد لكل لغة، ويصعب عليه التعامل مع الاستثناءات اللغوية.
مثال: الترجمة الإحصائية
- نعطيه بيانات متوازية (جمل وترجمتها).
- يستنتج الأنماط والاحتمالات وحده.
- أسهل في الصيانة والتكيف.
الترجمة الإحصائية بالبيانات المتوازية
هنا يبدأ تعلم الآلة. نحن لا نعطيه قواعد بل نعطيه بيانات متوازية (جمل مقابل ترجتمها)، وهو يستنتج الأنماط والاحتمالات وحده.
from collections import defaultdict, Counter
# SMT: Learning from data (Parallel Corpus)
parallel_data = [
("the cat", "el gato"),
("the house", "la casa"),
("the black cat", "el gato negro"),
("the black house", "la casa negra")
]
def train_smt(data):
# Count occurrences of source-target word pairs
counts = defaultdict(Counter)
for src, tgt in data:
for s_word in src.split():
for t_word in tgt.split():
counts[s_word][t_word] += 1
# Calculate Probability: P(target | source)
model = {}
for s_word, t_variants in counts.items():
total = sum(t_variants.values())
model[s_word] = {t: count / total for t, count in t_variants.items()}
return model
def smt_translate(sentence, model):
words = sentence.lower().split()
# Pick the target word with the highest probability
return " ".join([max(model[w], key=model[w].get) for w in words])
model = train_smt(parallel_data)
print(smt_translate("the black cat", model))
# Output: el gato negroملخص الفرق
| الميزة | القواعد (RBMT) | الإحصاء (SMT) |
|---|---|---|
| المصدر | علماء لغويات | بيانات ضخمة |
| المنطق | “إذا.. افعل” | احتمالات وأنماط |
| الصيانة | صعبة | سهلة |
ملخص الفرق في جدول
| الميزة | القواعد (RBMT) | الإحصاء (SMT) |
|---|---|---|
| المصدر الأساسي | علماء لغويات وقواميس | بيانات ضخمة (Big Data) |
| المنطق | “إذا حدث هذا، افعل ذاك” | حساب احتمالات وأنماط |
| الصيانة | صعبة (تعديل القواعد يدوياً) | سهلة (إضافة بيانات أكثر فقط) |
ومن ميزات تعلم الآلة: التكيُّف مع تغير اللغة بل مع استعمالات الألفاظ في السياقات المختلفة مع اختلاف الأزمنة.
Mitchell, Tom. 2015. "Introduction to Machine Learning (10-601)". Carnegie Mellon University. 2015. https://www.cs.cmu.edu/~ninamf/courses/601sp15/lectures.shtml.
Shalev-Shwartz, Shai, و Shai Ben-David. 2014. Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press. https://doi.org/10.1017/cbo9781107298019.