import numpy as np
import pandas as pd
from sklearn import preprocessingترميز المقادير المنفصلة (Encoding)
يجب ترميز البيانات الوصفية بصيغة عددية لنتعامل معها في معظم خوارزميات تعلم الآلة.
فأما الأوصاف المرتبة (Ordinal): كالأحجام (صغير، وسط، كبير) أو المراكز (الأول، الثاني، الثالث) ونحو ذلك فيتم ترميزها بالأعداد مرتَّبة على نحو: (1, 2, 3) باستعمال OrdinalEncoder.
وهي وغير المرتَّبة (Nominal): يمكن ترميزهما بالصفر والواحد، وجودًا وعدمًا، بعدد القيَم الفريدة للصفة. ويستعمل لذلك OneHotEncoder.
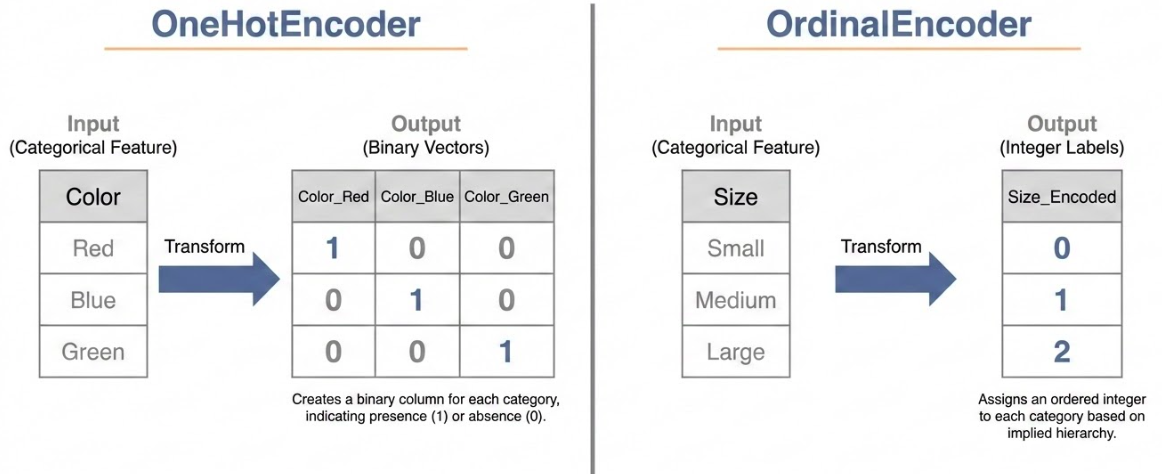
المُرمِّز الرُّتَبي (OrdinalEncoder)
from sklearn.preprocessing import OrdinalEncoder
# Specify the order of categories
categories = [
['low', 'medium', 'high'], # categories of first feature
['1st', '2nd', '3rd'], # categories of second feature
]
encoder = OrdinalEncoder(
categories=categories,
handle_unknown='use_encoded_value', # means that if we encounter an unknown category, we will encode it as a specific value
unknown_value=-1
)
# We want a pandas DataFrame as output rather than a NumPy array (default)
encoder = encoder.set_output(transform='pandas')df = pd.DataFrame({
'risk': ['low', 'medium', 'low', 'low', 'high'],
'class': ['1st', '3rd', '2nd', '1st', '3rd'],
})
df| risk | class | |
|---|---|---|
| 0 | low | 1st |
| 1 | medium | 3rd |
| 2 | low | 2nd |
| 3 | low | 1st |
| 4 | high | 3rd |
encoder.fit_transform(df)| risk | class | |
|---|---|---|
| 0 | 0.0 | 0.0 |
| 1 | 1.0 | 2.0 |
| 2 | 0.0 | 1.0 |
| 3 | 0.0 | 0.0 |
| 4 | 2.0 | 2.0 |
المُرمِّز الأحادي (OneHotEncoder)
from sklearn.preprocessing import OneHotEncoder
# Create a OneHotEncoder instance
encoder = OneHotEncoder(
handle_unknown='infrequent_if_exist',
sparse_output=False, # <-- output is a dense array
)
encoder.set_output(transform='pandas')OneHotEncoder(handle_unknown='infrequent_if_exist', sparse_output=False)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
df_train = pd.DataFrame({
'color': ['Red', 'Blue', 'Green', 'Green']
})
df_train| color | |
|---|---|
| 0 | Red |
| 1 | Blue |
| 2 | Green |
| 3 | Green |
# Fit and transform the data
encoder.fit_transform(df_train)| color_Blue | color_Green | color_Red | |
|---|---|---|---|
| 0 | 0.0 | 0.0 | 1.0 |
| 1 | 1.0 | 0.0 | 0.0 |
| 2 | 0.0 | 1.0 | 0.0 |
| 3 | 0.0 | 1.0 | 0.0 |
df_test = pd.DataFrame({
'color': ['Blue', 'Green', 'dragonfruit']
})
df_test| color | |
|---|---|
| 0 | Blue |
| 1 | Green |
| 2 | dragonfruit |
# 4. Transform
result = encoder.transform(df_test)
result| color_Blue | color_Green | color_Red | |
|---|---|---|---|
| 0 | 1.0 | 0.0 | 0.0 |
| 1 | 0.0 | 1.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 |
مشكلة الذاكرة في التمثيل الأحادي
ومما يجب التنبيه عليه: أن كل صفة فريدة يتم إنشاء عمود مستقل لها. وذلك قد يتسبب في امتلاء الذاكرة، لذلك فإننا نحدُّ من عدد الصفات باعتبار القيَم الفريدة المتكررة أكثر من min_frequencies من المرات، ثم حدُّ عدد الصفات بـ max_categories.
“على سبيل المثال، سنقوم بحساب عدد الأعمدة وحجم الذاكرة المضافة الناتجة عن ترميز المتغيرات الوصفية في مجموعة بيانات Ames Housing:”
| المعيار | قبل الترميز | بعد الترميز الأحادي | الزيادة |
|---|---|---|---|
| عدد الأعمدة | ~46 | ~318 | ~6.9x |
| الحجم | ~0.15 MB | ~7.10 MB | ~47.3x |
لتفاصيل إنشاء هذا الجودل، راجع: إبراز مشكلة الذاكرة في الترميز الأحادي.
الحل
- استخدم
min_frequencyلتقليل عدد الأعمدة عن طريق تجميع الفئات غير المتكررة في عمود واحد. - استخدم
max_categoriesلتحديد الحد الأقصى لعدد الأعمدة الإجمالي (بما في ذلك عمود الفئات النادرة).
يقبل المرمز الأحادي (OneHotEncoder) تجميع الفئات النادرة في مخرج واحد لكل ميزة، كما هو موضح في الجدول أدناه:
| العامل | النوع | القاعدة | الوصف |
|---|---|---|---|
min_frequency |
int |
\(\ge 1\) | تُعتبر الفئات التي يقل تكرارها عن هذا العدد الصحيح فئات نادرة. |
| _ | float |
\((0.0, 1.0)\) | تُعتبر الفئات التي يقل تكرارها عن هذه النسبة من إجمالي العينات فئات نادرة. |
max_categories |
int |
\(> 1\) | يضع حداً أقصى لإجمالي عدد الميزات الناتجة (output features)، بما في ذلك فئة “النادرة”. |
| _ | None |
افتراضي | لا يوجد حد أقصى لعدد الميزات الناتجة. |
X = np.array([
['cat'] * 20 +
['rabbit'] * 10 +
['snake'] * 6 +
['dragon'] * 3 +
['dinosaur'] * 2
], dtype=str).T
X.shape(41, 1)تذكر: أن ضرب القائمة بعدد صحيح يكرر العناصر. وجمع القائمة مع القائمة يدمجهما في قائمة جديدة.
enc = preprocessing.OneHotEncoder(
min_frequency=6,
max_categories=3,
handle_unknown='infrequent_if_exist',
sparse_output=False,
)
enc.set_output(transform='pandas')
enc.fit(X)OneHotEncoder(handle_unknown='infrequent_if_exist', max_categories=3,
min_frequency=6, sparse_output=False)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
- لاحظ كيف سيتم تعيين كل من
'dragon'و'dinosaur'إلى الترميز:[0., 0., 1.](وهو الترميز المشترك لجميع الفئات النادرة). - وفقاً لآلية عمل
OneHotEncoder،بما أننا قيدنا معاملmax_categoriesبـ 3، فإن'snake'لم تُدرج كفئة منفصلة رغم استيفائها لشرطmin_frequency؛ وذلك لأن الفئة الثالثة حُجزت لتمثيل الفئات النادرة.
enc.transform(np.array([
['rabbit'],
['rabbit'],
['cat'],
['snake'],
['dragon'],
['dinosaur'],
]))| x0_cat | x0_rabbit | x0_infrequent_sklearn | |
|---|---|---|---|
| 0 | 0.0 | 1.0 | 0.0 |
| 1 | 0.0 | 1.0 | 0.0 |
| 2 | 1.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 1.0 |
| 4 | 0.0 | 0.0 | 1.0 |
| 5 | 0.0 | 0.0 | 1.0 |
print("Categories:", enc.categories_)
print("Infrequent categories:", enc.infrequent_categories_)Categories: [array(['cat', 'dinosaur', 'dragon', 'rabbit', 'snake'], dtype='<U8')]
Infrequent categories: [array(['dinosaur', 'dragon', 'snake'], dtype='<U8')]- الترميز الجغرافي (Geocoding) يُنتج معلومات خطوط الطول والعرض، قد يكون خياراً أفضل في كثير من الأحيان للأوصاف المكانية.
- للمزيد، راجع: 7.3.4. Encoding categorical features.