from sklearn.datasets import fetch_openml
ames_housing = fetch_openml(name="house_prices", as_frame=True)
data = ames_housing.data
target = ames_housing.targetخطوط الإنتاج (Pipelines)
نتعلم في هذا الدرس: التعامل مع الميزات العددية والوصفية معًا في خط معالجة واحد.
- تعويض القيم المفقودة
- توحيد القياس للميزات العددية
- ترميز الميزات الوصفية
المعالجة القبلية (Preprocessing)
يسبق أي نموذج معالجة قبليَّة (Preprocessing) للخصائص العددية والوصفية كالتقييس والترميز وملء الفراغات، وقد تتعدد هذه الخطوات لكل خاصية.
خط الإنتاج (Pipeline)
خط الإنتاج (Pipeline) هو صياغة للخطوات المتفرقة على نسق واحد، يكون في آخره النموذج؛ بحيث يتم التعامل مع الخط كاملاً كما لو أنه هو النموذج. وذلك ليتم ضبط النموذج مع جميع المعالجات القبليَّة له جُملَةً واحدة؛ فالتغيير فيها أو في عوامل النموذج، كلاهُما يؤثر في النتيجة النهائية: التنبؤ.
أولها: الإجمال (عكس التفصيل): فبدلاً من كتابة كود طويل لكل خطوة كهذا:
step_1 = SimpleImputer()
X_train = step_1.fit_transform(X_train)
step_2 = StandardScaler()
X_train = step_2.fit_transform(X_train)
model = SGDRegressor()
model.fit(X_train, y_train).. المسار يجمع الخطوات في سلسلة واحدة، يتم فيها تحديد كل خطوة وتسميتها، على النحو التالي
pipe = Pipeline(
steps=[
('imputer', SimpleImputer()),
('scaler', StandardScaler()),
('regressor', SGDRegressor()),
]
).. فيكفي استدعاء fit() مرة واحدة على بياناتك لملاءمة سلسلة الخطوات جملةً واحدة:
pipe.fit(X_train, y_train)أما transform() فيتم استدعاؤها عند الحاجة: عند التنبؤ أو التقييم.
وكذلك عند التنبؤ، لا حاجة لمعرفة تفاصيل التحويلات ثم كتابتها واحدة واحدة، بل هي محفوظة كقطعة متكاملة:
pipe.predict(X_new)وكذلك التقييم:
pipe.score(X_test, y_test)ما هي فلسفة مكونات خط المعالجة (Pipeline)؟
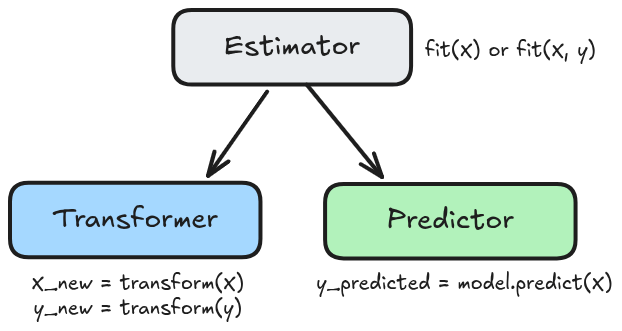
نتعلم في هذا الدرس: الانتقال من النموذج إلى خط المعالجة (Pipeline)، حيث جميع خطواته هي أحد أمرين لا ثالث لهما. ففي مكتبة sklearn تم تسمية الوحدة في مسار المعالجة باسم المقدِّر (Estimator)، وهي إما:
- محوِّل (Transformer):
- يُحصي مقادير من البيانات:
.fit(X) - يُحوِّل البيانات بناءً على المقادير المحسوبة:
.transform(X)
- يُحصي مقادير من البيانات:
- متنبئ (Predictor):
- يلائم البيانات:
.fit(X, y) - يتنبأ بالنتائج:
.predict(X) - يُقيَّم:
.score(X, y)
- يلائم البيانات:
لنفصّل الأمر:
المحوّل (Transformer)
ملاحظة: قد تضيف المحولات أعمدة أو تزيلها. لكنها لا تضيف بيانات جديدة (صفوف) أو تزيلها.
وإليك أمثلة للمحولات وعمل كلا الإجرائين فيها:
| المحول | التقدير: fit |
التحويل: transform |
|---|---|---|
SimpleImputer('mean') |
يحصي المتوسط. | يملأ الفراغات بالمتوسط. |
StandardScaler |
يحسب المتوسط والانحراف المعياري. | يحول البيانات لتكون على المقياس الطبيعي. |
OneHotEncoder |
يحدد الصفات الفريدة ويخصص ترميزاً أحاديًّا لكل منها. | يطبق الترميزات على العينات ليحولها إلى أعمدة أحادية. |
OrdinalEncoder |
يحدد الصفات الفريدة ويخصص لها ترتيباً عدديًا. | يطبق الترميز ويحول الصفات إلى قيم عددية مرتبة. |
المتنبئ (Predictor)
مثل النماذج: LinearRegression, SGDRegressor, KNeighborsClassifier
فأما إجراءاته فهي:
- التقدير:
fit(X, y)وهي ملاءمة النموذج للبيانات وفق خوارزمية التعلم الآلي المحددة. وهنا يحصل التعليم / التدريب. - التنبؤ:
predict(X)تطبّق النموذج على الحالات الجديدة فقط.
الهيكل التنظيمي للمكتبة
وبهذا يتبيَّنُ لك كيف تم تقسيم المكتبة على نحو هذا الشكل:
"""
sklearn/
├── preprocessing/ <-- (Transformers)
│ ├── StandardScaler
│ ├── OneHotEncoder
│ └── ...
├── impute/ <-- (Transformers)
│ ├── SimpleImputer
│ └── ...
├── linear_model/ <-- (Predictors)
│ ├── LinearRegression
├── SGDRegressor
│ └── ...
├── neighbors/ <-- (Predictors)
│ ├── KNeighborsClassifier
│ └── ...
├── ensemble/ <-- (Predictors)
│ ├── RandomForestClassifier
│ └── ...
└── pipeline/ <-- (The Glue)
└── Pipeline
"""حيث يتم استيرادها على هذا النحو:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegressionخلاصة خط الإنتاج
| العنصر | الإجراء | الغرض |
|---|---|---|
| المُقدِّر (Estimator) | fit() |
لملاءمة المعاملات من البيانات. |
| المُحوِّل (Transformer) | transform() |
لاستخدام المعاملات التي تم تعلمها أو حسابها على البيانات. |
| المُتنبِّئ (Predictor) | predict() |
لاستخدام المعاملات التي تم تعلمها للتنبؤ. |
| المُتنبِّئ (Predictor) | score() |
لتقييم جودة الملاءمة (الأعلى أفضل). |
فيما يلي مثال لكيفية ذلك ..
1. تحميل مجموعة البيانات
نحتاج إلى تعريف البيانات والهدف (target). هنا نبني نموذج انحدار (regression model).
نستعرض الصفوف الأولى من إطار البيانات (dataframe).
data.head()| Id | MSSubClass | MSZoning | LotFrontage | LotArea | Street | Alley | LotShape | LandContour | Utilities | ... | ScreenPorch | PoolArea | PoolQC | Fence | MiscFeature | MiscVal | MoSold | YrSold | SaleType | SaleCondition | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 60 | RL | 65.0 | 8450 | Pave | NaN | Reg | Lvl | AllPub | ... | 0 | 0 | NaN | NaN | NaN | 0 | 2 | 2008 | WD | Normal |
| 1 | 2 | 20 | RL | 80.0 | 9600 | Pave | NaN | Reg | Lvl | AllPub | ... | 0 | 0 | NaN | NaN | NaN | 0 | 5 | 2007 | WD | Normal |
| 2 | 3 | 60 | RL | 68.0 | 11250 | Pave | NaN | IR1 | Lvl | AllPub | ... | 0 | 0 | NaN | NaN | NaN | 0 | 9 | 2008 | WD | Normal |
| 3 | 4 | 70 | RL | 60.0 | 9550 | Pave | NaN | IR1 | Lvl | AllPub | ... | 0 | 0 | NaN | NaN | NaN | 0 | 2 | 2006 | WD | Abnorml |
| 4 | 5 | 60 | RL | 84.0 | 14260 | Pave | NaN | IR1 | Lvl | AllPub | ... | 0 | 0 | NaN | NaN | NaN | 0 | 12 | 2008 | WD | Normal |
5 rows × 80 columns
2. أخذ مجموعة فرعية من الميزات
من أجل البساطة، يمكننا اختيار بعض الميزات (features) والاكتفاء بهذه المجموعة الفرعية من البيانات:
numeric_features = ["LotArea", "FullBath", "HalfBath"]
categorical_features = ["Neighborhood", "HouseStyle"]
data = data[numeric_features + categorical_features]3. المعالجة الأولية (Pre-processing)
نادراً ما تكون البيانات الخام جاهزة للاستخدام الفوري في نماذج تعلم الآلة. نحتاج غالباً إلى خطوات معالجة مثل:
- التعامل مع القيم المفقودة.
- ترميز المتغيرات الوصفية (Categorical Encoding).
- تقييس المتغيرات العددية (Scaling).
لنسهل الأمر، سنختر مجموعة محددة من الأعمدة للعمل عليها:
أ. التعامل مع القيم المفقودة (Imputation)
القيم المفقودة مشكلة شائعة. لا تقبل معظم الخوارزميات وجود فراغات في البيانات.
استراتيجيات التعويض (SimpleImputer):
mean(المتوسط): تُستخدم مع البيانات العددية ذات التوزيع الطبيعي.median(الوسيط): الأفضل للبيانات العددية التي تحتوي على قيم شاذة (Outliers).most_frequent(الأكثر تكراراً): تُستخدم غالباً مع البيانات الوصفية (Categorical).constant(قيمة ثابتة): تعويض القيمة المفقودة بقيمة محددة (مثلاً “Unknown” أو 0).
كيف ندمجها في خط المعالجة؟ عند استخدام Pipeline، نضمن أن عملية التعويض (imputer.fit) تتم فقط على بيانات التدريب، ثم تُطبق القواعد المستخلصة على بيانات الاختبار. هذا يمنع تسرب المعلومات.
3.1 الميزات العددية
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
numeric_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="median")),
(
"scaler",
StandardScaler(),
),
]
)3.2 الميزات الوصفية
from sklearn.preprocessing import OneHotEncoder
categorical_transformer = OneHotEncoder(handle_unknown="ignore")4. تعيين التحويل للأعمدة المراد تحويلها
ثلاث نقاط يجب تذكرها:
- محوّل الأعمدة (ColumnTransformer) رابط يُستخدم لاختيار الميزات التي تُطبَّق عليها التحويلات المحددة.
- اتحاد الميزات (FeatureUnion) رابط يربط مخرجات المحوّلات في فضاء ميزات مركّب (composite feature space).
- أخيراً، لتحويل الهدف (target) (مثلاً تحويل لوغاريتمي لـ y) استخدم متنبئ الهدف المحوّل (TransformedTargetRegressor) رابط.
from sklearn.compose import ColumnTransformer
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
("cat", categorical_transformer, categorical_features),
]
)5. تعريف المسار
تعريف نموذج الانحدار (regression model).
أحياناً نسمّي المسار بالكامل النموذج (model). لذلك نسمي المتنبئ (predictor) بهذا الاسم.
from sklearn.linear_model import SGDRegressor
predictor = SGDRegressor(loss="squared_error")ربط الخطوات بالمتنبئ (predictor).
pipe = Pipeline(
steps=[
("preprocessor", preprocessor),
("regressor", predictor),
]
)
pipePipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('num',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median')),
('scaler',
StandardScaler())]),
['LotArea', 'FullBath',
'HalfBath']),
('cat',
OneHotEncoder(handle_unknown='ignore'),
['Neighborhood',
'HouseStyle'])])),
('regressor', SGDRegressor())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
['LotArea', 'FullBath', 'HalfBath']
Parameters
Parameters
['Neighborhood', 'HouseStyle']
Parameters
Parameters
قياس التعميم
أحد أهم المفاهيم في تعلم الآلة هو قدرة النموذج على التعميم (Generalization)، أي أداؤه على بيانات جديدة لم يرها أثناء التدريب.
يقع الكثير من المبتدئين في خطأ فادح وهو تقييم النموذج على نفس البيانات التي تدرب عليها. هذا يعطي نتائج مضللة وتفاؤلية جداً.
# WRONG
# pipe.fit(data, target)وضع مجموعة للاختبار
يجب تقسيم البيانات إلى قسمين:
- مجموعة التدريب (Training Set): تُستخدم لتدريب النموذج.
- مجموعة الاختبار (Test Set): تُحجب عن النموذج تماماً، وتُستخدم فقط في النهاية لتقييم أدائه.
from sklearn.model_selection import train_test_split
# تقسيم البيانات: 80% للتدريب و 20% للاختبار
X_train, X_test, y_train, y_test = train_test_split(
data, target, test_size=0.2, random_state=42
)
print(f"Shape of X_train: {X_train.shape}")
print(f"Shape of X_test: {X_test.shape}")Shape of X_train: (1168, 5)
Shape of X_test: (292, 5)والآن: الملاءمة، لاحظ كيف يتغيّر لون الرسم بعد التدريب.
pipe.fit(X_train, y_train)Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('num',
Pipeline(steps=[('imputer',
SimpleImputer(strategy='median')),
('scaler',
StandardScaler())]),
['LotArea', 'FullBath',
'HalfBath']),
('cat',
OneHotEncoder(handle_unknown='ignore'),
['Neighborhood',
'HouseStyle'])])),
('regressor', SGDRegressor())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
Parameters
['LotArea', 'FullBath', 'HalfBath']
Parameters
Parameters
['Neighborhood', 'HouseStyle']
Parameters
Parameters
6. تقييم الأداء على بيانات الاختبار
score = pipe.score(X_test, y_test)
print(f"R² Score on Test Set: {score:.3f}")R² Score on Test Set: 0.663ملاحظة: تقييم النموذج (Model Evaluation) يحتاج نقاشاً مستقلاً، لكن نعرضه هنا للتكميل.
طريقة أخرى لإنشاء خط الإنتاج: make_pipeline
إضافة: يمكننا بدلاً من ذلك استخدام واجهة الدوال (functional API): make_column_transformer و make_pipeline، ولا تتطلبان ولا تسمحان بتسمية المُقدّرات يدوياً؛ بل تُعيَّن أسماؤها تلقائياً بأحرف صغيرة من أنواعها.
from sklearn.compose import make_column_transformer
from sklearn.pipeline import make_pipeline
numeric_transformer = make_pipeline(
SimpleImputer(strategy="median"), StandardScaler()
)
categorical_transformer = OneHotEncoder(handle_unknown="ignore")
preprocessor = make_column_transformer(
(numeric_transformer, numeric_features),
(categorical_transformer, categorical_features),
)
pipe = make_pipeline(preprocessor, SGDRegressor())
pipe.fit(X_train, y_train)