Module 1 - Session 1: Introduction to PyTorch and Neural Networks
Module 1 Overview
What will we learn?
Distinguish Deep Learning from Machine Learning
What are neurons and how do they learn?
Why learn the PyTorch framework?
The ML Pipeline
Activation Functions
Tensors (PyTorch’s data structures)
Welcome to Module 1 of PyTorch Fundamentals. This module will take you from understanding why PyTorch exists to building and training your first neural network. We’ll start with the motivation behind PyTorch, then dive into the fundamental building blocks, and end with hands-on implementation.
The question chain shows how each session builds on the previous one: understanding PyTorch’s philosophy leads to understanding neural networks, which leads to understanding the pipeline, which leads to implementation.
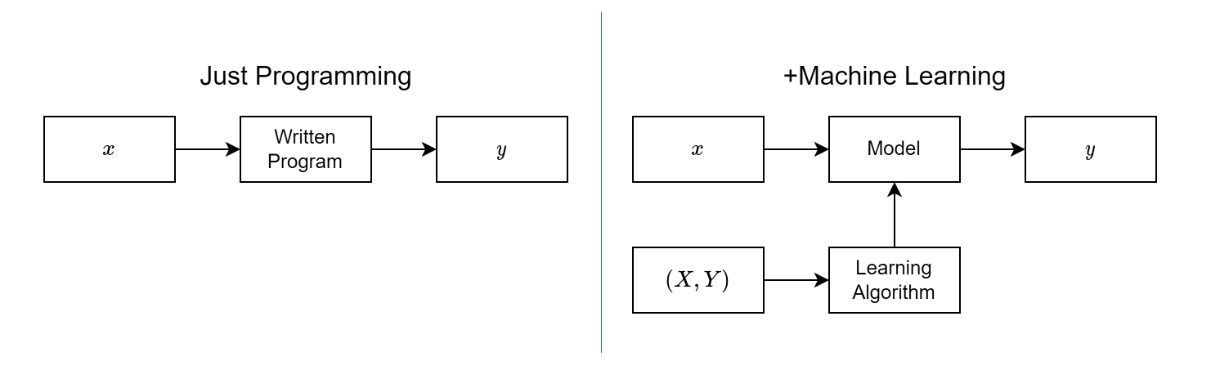
Machine Learning vs Traditional Programming
ML vs Traditional Programming
To understand why we need PyTorch and neural networks, we need to understand how machine learning differs from traditional programming.
In traditional programming, you write rules that transform inputs to outputs. If the customer buys a camera, recommend lenses. But what if it was a gift? What if they already have five lenses? You’d need thousands of rules for every exception.
In machine learning, you give the system examples of inputs and outputs, and it learns the rules for you. Deep learning takes this further using neural networks - they can learn complex patterns from data that would be impossible to encode as rules.
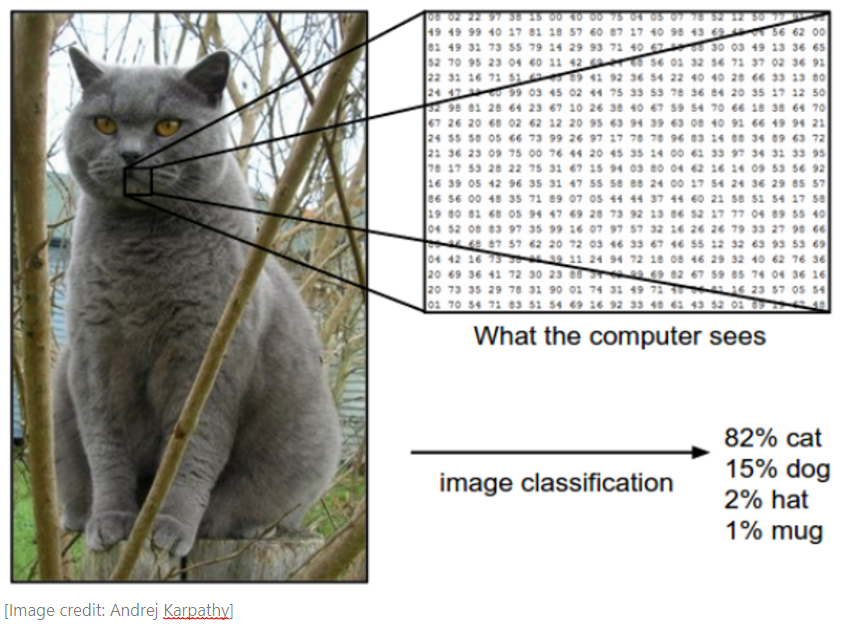
The Challenge: Unstructured Data
High-Dimensional Data
224 × 224 image = 50,176 pixels 1080p image = 2,073,600 pixels
Here’s why we need deep learning. Traditional machine learning works well with structured data - clean tables with columns and rows. But much of the world’s data is unstructured: images, videos, audio, text.
A single image can have millions of pixels. You can’t represent this as columns in a DataFrame and use classical ML models - it would be completely impractical. Neural networks can learn to recognize patterns in this high-dimensional data directly from the raw pixels.
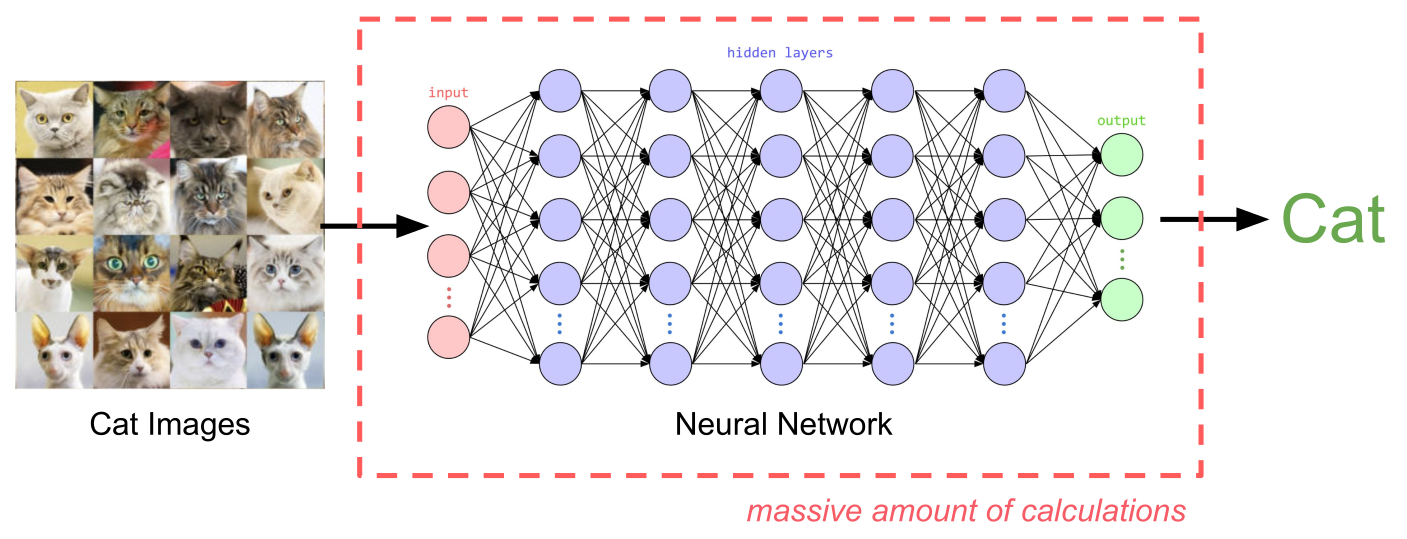
Neural Networks: Universal Approximators
Neural Network Processing
Representation Learning from raw data
Neural networks are known as universal approximators because they can approximate any function given enough data and computational power. They solve the problem of representation learning - automatically discovering meaningful features from raw data.
Instead of manually engineering features (like “does this image have edges?” or “are there circular shapes?”), neural networks learn to spot patterns formed by pixels and represent them as progressively more abstract and meaningful features. The final layer uses these learned features to make predictions.
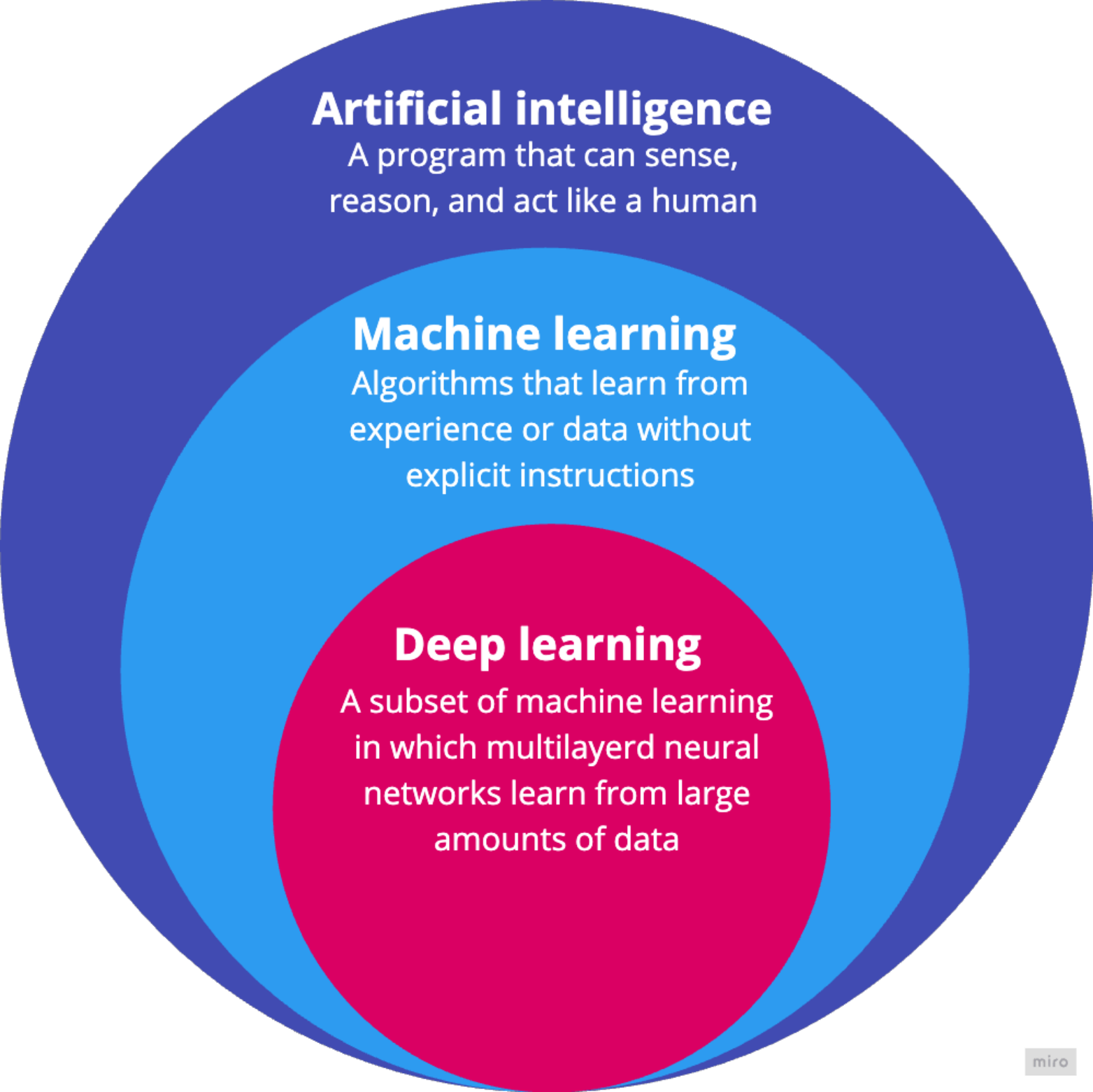
Deep Learning vs Machine Learning
AI, ML, DL Venn Diagram
Deep Learning = Neural Networks with multiple layers
Deep learning is a subset of machine learning based on artificial neural networks with multiple layers - hence “deep.” While a basic neural network might have one or two hidden layers, deep learning models often contain dozens or even hundreds of layers.
The key difference: deep learning excels at unstructured data (images, speech, text) and learns hierarchical representations directly from raw data, while traditional ML often requires manual feature engineering and works well on structured/tabular data.
ML vs DL
Performance Envelope Competitive on structured/tabular data
Dominant in unstructured domains (vision, speech, NLP)
Data Regime Performs well with small to medium datasets
Typically requires large-scale datasets to generalize well
Computational Cost Often CPU-friendly; faster training
GPU/TPU-dependent; computationally expensive
Model Class Linear models, Decision Trees, Random Forests, Gradient Boosting
Multi-layer Neural Networks, CNNs, RNNs, Transformers
Feature Engineering Relies heavily on manual feature design informed by domain knowledge
Learns hierarchical representations directly from raw data
Interpretability Many models are interpretable (linear models, trees)
Largely opaque; “black box” nature requiring post-hoc explainability
Deep learning isn’t always the right solution. It’s great when traditional rule-based approaches fail, when environments change continuously, or when you need to discover patterns in massive datasets.
But it’s not good when you need to explain decisions, when simple rules work fine, when errors can’t be tolerated, or when you have limited data. The key is choosing the right tool for the job.
Many Deep Learning Applications
Vision:
Language:
Data Annotation
Models must be fine-tuned on annotated data
Start Simple: The Delivery Problem
Scenario: Local delivery company, 30-minute promise
New order: 7 miles away
Question: Can you get there in under 30 minutes?
Now let’s ground these concepts with a concrete problem. You work for a local delivery company that promises 30-minute delivery. You’ve been late three times, and one more late delivery could cost you your job. A new order comes in - 7 miles away. Do you take it?
This is a perfect problem for a neural network to solve, if we have historical data. And we’ll use the simplest possible neural network - just one neuron - to tackle it.
Historical Delivery Data
Can you see the pattern?
Here’s some historical delivery data. Can you see the pattern? 5 miles took 22.2 minutes, 6 miles took 25.6 minutes. If we plot this data, we’d see the points follow a straight line. A good predictive model would be… a line!
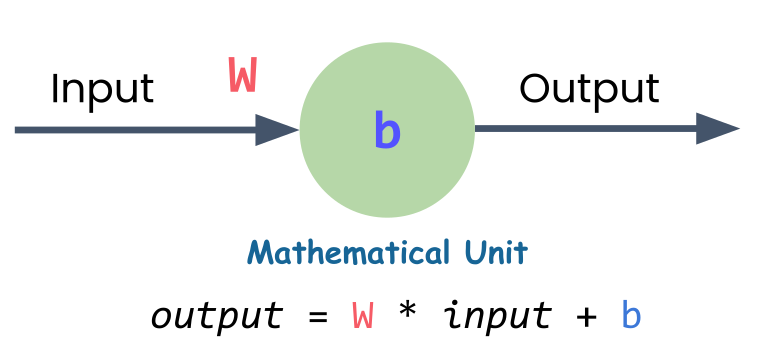
If we know the equation for that line, we can predict new values. And here’s the key insight: a single neuron is just a linear equation with two parameters - the weight and the bias.
A Single Neuron = A Linear Equation
Single Neuron
\(y = Wx + b\)
W = weight (slope)b = bias (y-intercept)x = input (distance)y = output (predicted time)
A single neuron is just a linear equation. That’s the equation for a straight line. The neuron needs to find the right values for W (weight) and b (bias) to create the best-fitting line through all the data points.
That search for the best values - that’s the learning in machine learning. The neuron starts with random values, measures how wrong its predictions are, and gradually adjusts W and b to improve.
How Does a Neuron Learn?
Start with random weight and bias
Make predictions
Measure error (how far off?)
Use calculus to find adjustment direction
Take small step toward better values
Repeat hundreds/thousands of times
Here’s how the learning process works. The neuron starts with random values for weight and bias. It makes predictions and measures how far off each prediction is from the actual data. The further off, the bigger the total error.
Then it uses calculus (specifically, gradient descent) to figure out which direction to adjust the weight and bias. It’s essentially asking: “If I increase the weight just a little, does the error go up or down?” Once it figures that out, it takes a small step in the right direction, measures the error again, and repeats.
This process happens hundreds or thousands of times until the neuron finds values close to the best possible ones.
Layers and Networks
Neural Network Structure
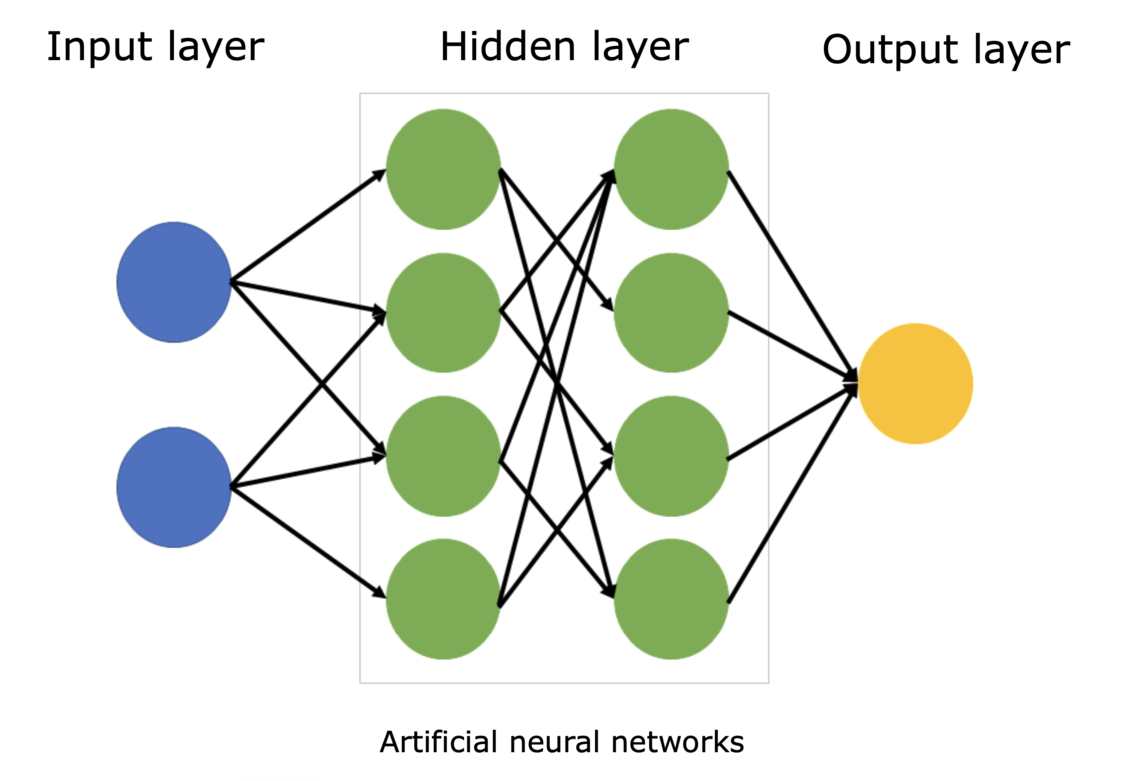
Layer: group of neurons with same inputsHidden layers: layers between input and outputNetwork: connected layers
When you connect neurons together, you get layers. A layer is simply a group of neurons that all take the same inputs. When you connect one layer’s outputs to the next layer’s inputs, you’ve built a network.
The first layer takes in your raw data (distance, time of day, weather). The last layer gives your prediction (delivery time). All those layers in between are called hidden layers because you never directly set or see their values.
Soon, you’ll see how easy it is to stack these layers together in PyTorch. But for now, we’ll continue with just one neuron to build the foundation.
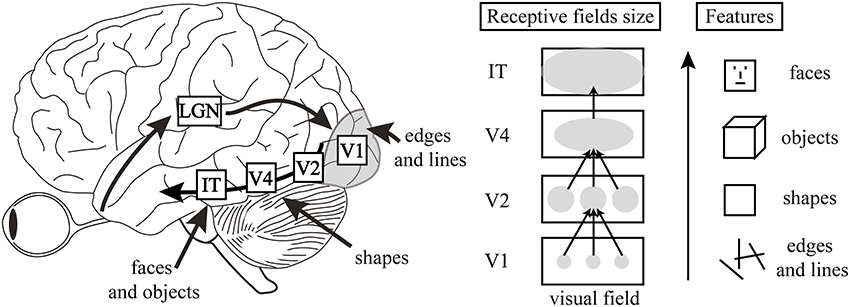
Analogy: Visual Cortex
Hierarchical Feature Extraction: From Retinal Input to Complex Object Recognition in the Ventral Stream.
Visual Cortex High-Level Features
Deep neural networks are like the visual cortex of the brain. They start with simple features like edges and shapes, and build up to more complex features like objects and scenes.
PyTorch
PyTorch is an open-source deep learning framework designed to accelerate the path from research prototyping to production deployment. Originally developed by Meta’s AI Research lab (FAIR) and released in 2016, it is now governed by the PyTorch Foundation under the Linux Foundation.
PyTorch Logo
Why PyTorch?
import torch= torch.tensor([2.0 ])= torch.tensor([3.0 ])= a + bprint (result) # tensor([5.]) Simple. Pythonic. Powerful.
Let me show you what makes PyTorch special with a simple example. Adding two numbers in PyTorch looks just like regular Python code. This simplicity wasn’t always the case in deep learning frameworks.
The key insight here is that PyTorch makes deep learning feel like writing normal Python. This wasn’t true of early frameworks, which required complex setup and compilation steps just to do simple operations.
The Problem with Early Frameworks
Static Computational Graphs
Define everything upfront
Compile before running
No flexibility to change
Cryptic error messages
No standard Python debugging
Early deep learning frameworks used something called static computational graphs. Think of it like a factory assembly line - you had to design the entire production process before you could run anything. If you made a mistake or wanted to experiment, you had to stop everything, tear it down, and rebuild from scratch.
This made even simple operations complex. You couldn’t use normal Python if statements or loops. Error messages pointed to internal system code, not your actual mistakes. People spent more time fighting their tools than doing actual work.
PyTorch’s Solution
Dynamic Computation
Write clean Pythonic code
Use normal loops and if statements
Change anything, anytime
Error messages point to your code
Standard Python debugging
PyTorch emerged from researchers’ frustration with these limitations. The core principle: deep learning should feel like normal Python. You write clean code, and PyTorch handles the computational complexity behind the scenes.
This approach made PyTorch incredibly popular, especially in research where experimentation and flexibility are crucial. Today, it’s backed by a massive community and has become the go-to choice for everyone from students to cutting-edge AI researchers.
What’s Next?
The 6-stage ML pipeline
Building a neural network in PyTorch
Training your first model
Click here to go to Session 2: The ML Pipeline and Building Your First Model
In the next session, we’ll see the complete machine learning pipeline - the systematic process that every PyTorch project follows. Then you’ll build your first neural network and train it on this exact delivery problem. Just a few lines of PyTorch code will bring all these concepts to life.