# %pip install -U -q "openai" pandas seaborn matplotlibEmbeddings
Embeddings are numerical representations of real-world data - text, images, audio, videos, anything; usually learned via deep learning models trained using self-supervised methods.
For example, BERT is an embedding model: you input a text and out comes a vector of 768 numbers; representing the “meaning” of this text, as learned by BERT.
It is helpful to visualize embeddings as a 2D or 3D vector geometrically as in the figure below, where if two vectors (points) are close; then, the objects they represent are similar in meaining:
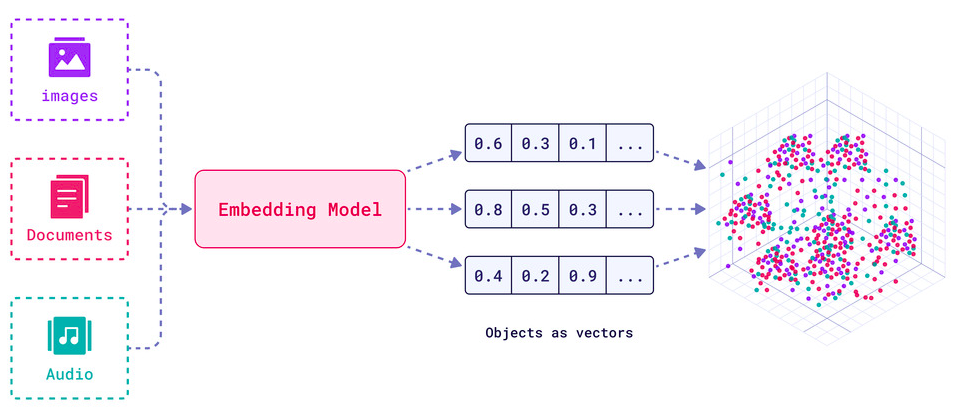
In reality, similarity metrics can be:
- Eucledian Distance measured by the straight line between the two points
- Cosine of the Angle between the two vectors, when they are imagined as pointed lines from the origin onto the points in the space
Embeddings are commonly used for:
- Search (where results are ranked by relevance to a query string)
- Clustering (where text strings are grouped by similarity)
- Recommendations (where items with related text strings are recommended)
- Anomaly detection (where outliers with little relatedness are identified)
- Diversity measurement (where similarity distributions are analyzed)
- Classification (where text strings are classified by their most similar label)
See: Embeddings | OpenRouter and Guides > Embeddings | OpenAI
Play around with embeddings
In this tutorial, you will use the OpenRouter API’s embedding endpoint (OpenAI-compatible) to explore similarity scores.
Prerequisites: - You need an OpenRouter API key stored in the OPENROUTER_API_KEY environment variable. Get your key at openrouter.ai/keys.
Setup
First, we’ll install the necessary libraries.
import os
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# from openai import OpenAISet up your API key
Ensure your OPENROUTER_API_KEY is set in your environment variables (e.g. in a .env file).
import requests
OPENROUTER_API_KEY = os.environ.get("OPENROUTER_API_KEY")
model_name = "nvidia/llama-nemotron-embed-vl-1b-v2:free"def embed(texts: list[str]):
response = requests.post(
"https://openrouter.ai/api/v1/embeddings",
headers={
"Authorization": f"Bearer {OPENROUTER_API_KEY}",
"Content-Type": "application/json",
},
json={
"model": model_name,
"input": texts,
},
)
data = response.json()
return data["data"]Calculate similarity scores
This example embeds some variations on the pangram, The quick brown fox jumps over the lazy dog, including spelling mistakes and shortenings of the phrase. Another pangram and a somewhat unrelated phrase have been included for comparison.
texts = [
'The quick brown fox jumps over the lazy dog.',
'The quick rbown fox jumps over the lazy dog.',
'teh fast fox jumps over the slow woofer.',
'a quick brown fox jmps over lazy dog.',
'brown fox jumping over dog',
'fox > dog',
# Alternative pangram for comparison:
'The five boxing wizards jump quickly.',
# Unrelated text, also for comparison:
'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus et hendrerit massa. Sed pulvinar, nisi a lobortis sagittis, neque risus gravida dolor, in porta dui odio vel purus.',
]embeddings = embed(texts)print("Count:", len(embeddings))
print("Dimensions (Size):", len(embeddings[0]["embedding"]))Count: 8
Dimensions (Size): 2048Define a short helper function that will make it easier to display longer embedding texts in our visualisation.
def truncate(t: str, limit: int = 50) -> str:
"""Truncate labels to fit on the chart."""
if len(t) > limit:
return t[:limit-3] + '...'
else:
return t
truncated_texts = [truncate(t) for t in texts]A similarity score of two embedding vectors can be obtained by calculating their inner product. If \(\mathbf{u}\) is the first embedding vector, and \(\mathbf{v}\) the second, this is \(\mathbf{u}^T \mathbf{v}\). As the API provides embedding vectors that are normalised to unit length, this is also the cosine similarity.
This score can be computed across all embeddings through the matrix self-multiplication: df @ df.T.
Note that the range from 0.0 (completely dissimilar) to 1.0 (completely similar) is depicted in the heatmap from light (0.0) to dark (1.0).
# Set up the embeddings in a dataframe.
df = pd.DataFrame([e["embedding"] for e in embeddings], index=truncated_texts)
# Perform the similarity calculation
sim = df @ df.T# Draw!
# plt.figure(figsize=(10, 8))
sns.heatmap(sim, annot=True, vmin=0, vmax=1, cmap="Greens")
plt.title("Semantic Similarity Heatmap")
plt.show()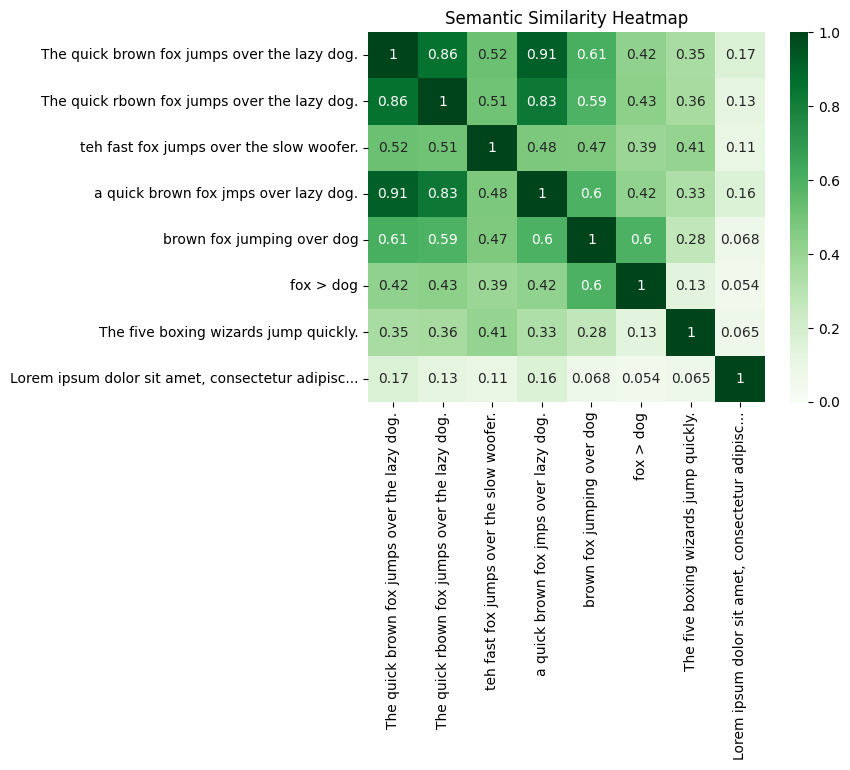
You can see the scores for a particular term directly by looking it up in the dataframe.
print(sim['The quick brown fox jumps over the lazy dog.'].sort_values(ascending=False))The quick brown fox jumps over the lazy dog. 1.000861
a quick brown fox jmps over lazy dog. 0.911227
The quick rbown fox jumps over the lazy dog. 0.855384
brown fox jumping over dog 0.608608
teh fast fox jumps over the slow woofer. 0.521211
fox > dog 0.421878
The five boxing wizards jump quickly. 0.350881
Lorem ipsum dolor sit amet, consectetur adipisc... 0.170421
Name: The quick brown fox jumps over the lazy dog., dtype: float64