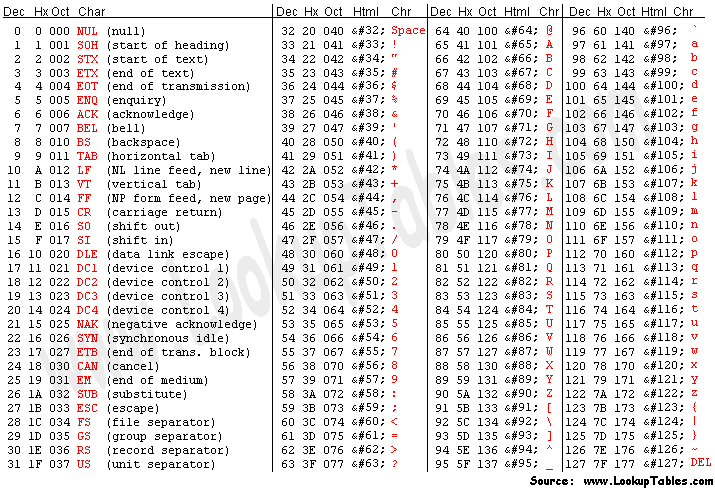
import string
print(string.ascii_letters)
print(string.punctuation)abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
قد يكون هذا الفصل على درجة زائدة من التفصيل عما تعودنا عليه في الفصول السابقة. لكن هذه التفاصيل ستكون مهمة حين تعالج أي نوع من البيانات الآتية من الخارج، لأنها كثيرًا ما تكون بيانات نصيَّة غير مقولَبة.
ترميز الحروف هي عملية تعيين أرقام للأحرف الرسومية مما يسمح بتخزينها ونقلها وتحويلها باستخدام الحواسيب الرقمية.
رموز ASCII تحتوي على 128 حرف للغة الإنجليزية وبعض علامات الترقيم. منها 95 فقط هي أحرف قابلة للطباعة أما البقية فتسمى أحرف تحكُّم (مثل حرف السطر الجديد \n ، وحرف الرجوع لبداية السطر \r).
ثم امتدت عن طريق رموز ANSII لتغطي أحرف إضافية (من 128 إلى 255) وهي الأحرف الاتينية للغات الأخرى.
لنستكشف السلاسل عن طريق حزمة من المكتبة الأساسية string. الآتي الأحرف اللاتينية الكبيرة والصغيرة، وعلامات الترقيم:
import string
print(string.ascii_letters)
print(string.punctuation)abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~واليوم رموز Unicode تحتوي على أكثر من مليون حرف لتغطية لغات العالم كافة: اللاتينية، اليونانية، السيريلية، الأرمنية، العبرية، العربية، السريانية، الثانا، الديفاناغارية، البنغالية، الجورموخية، الأورية، التاميلية، التيلوغوية، الكانادية، المالايالامية، السنهالية، التايلاندية، اللاوية، التبتية، الميانمارية، الجورجية، الهانغول، الإثيوبية، الشيروكية، الرموز الكندية الأصلية، الخميرية، المنغولية، الهان (الأيدوغراف الياباني، الصيني، الكوري)، الهيراغانا، الكاتاكانا، واليي. المصدر. وما يزال أول 128 حرف منها متطابق مع رموز ASCII.
ماذا يحصل لو كتبنا حروف عربية ثم حاولنا حفظ الملف بترميز ASCII ولم نحفظه بترميز Unicode؟
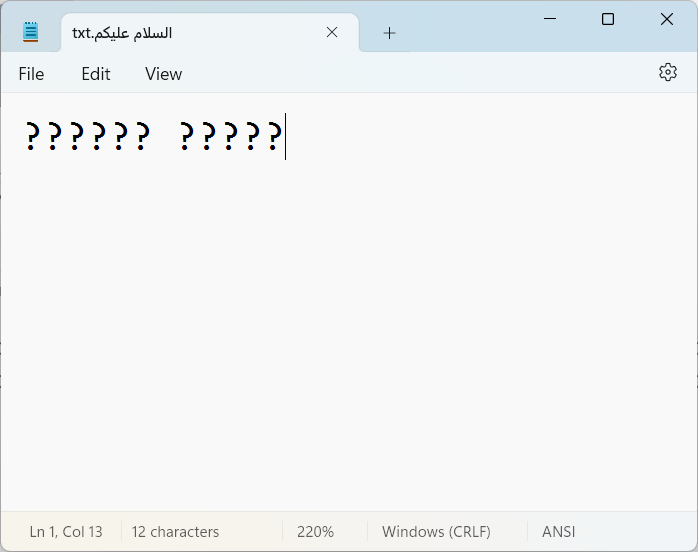
الخطأ يقول: “This file contains characters in Unicode format which will be lost if you save this file as an ANSI encoded text file. To keep the Unicode information, click Cancel below and then select one of the Unicode options from the Encoding drop down list. Continue?”
تمثيل النصوص في بايثون يكون عن طريق النوع str؛ يُعرَّف بكتابة سلسلة من الأحرف لكن في الواقع تتحول إلى سلسلة من رموز Unicode (أي: أرقام). هذا يعني أنها قد تكون سلسلة رموز لاتينية أو عربية أو صينية أو غير ذلك مما تحويه رموز Unicode.
الإجراء المبني ord() تقوم بتحويل الحرف إلى رقم الرمز. بينما chr() تعكس ذلك (من الرمز إلى الحرف).
على النقيض من سي وجافا؛ لا يوجد نوع خاص بالحرف الواحد (char) في بايثون.
print(ord("A"), ord("Z"))
print(chr(65), chr(90))
print(ord("a"), ord("z"))
print(ord("0"), ord("9"))65 90
A Z
97 122
48 57ماذا عن الحروف العربية؟ أين تقع في أرقام ترميز Unicode؟
# Arabic Unicode points are between 1536 and 1791
print(ord("أ"), hex(ord("أ")))
print(ord("ب"), hex(ord("ب")))
print(ord("ي"), hex(ord("ي")))
print(ord('َ'), hex(ord('َ')))
print(ord('ُ'), hex(ord('ُ')))1571 0x623
1576 0x628
1610 0x64a
1614 0x64e
1615 0x64fلمعرفة أرقام الحروف في نصٍّ ما؛ نستعمل التكرار هكذا:
s = "'Arabian'"
codes = []
for c in s:
codes.append(ord(c))
print(codes)[39, 65, 114, 97, 98, 105, 97, 110, 39]s = 'السَّلَامُ عَلَيْكُمْ'
codes = []
for c in s:
codes.append(ord(c))
print(codes)[1575, 1604, 1587, 1614, 1617, 1604, 1614, 1575, 1605, 1615, 32, 1593, 1614, 1604, 1614, 1610, 1618, 1603, 1615, 1605, 1618]فهذه هي الحروف في الواقع، إلا أننا نتعامل مع شيء مجرَّد في لغات البرمجة العالية غالبًا ما يسمى str.
راجع ويكيبيديا: النص العربي في Unicode لمزيد من التفاصيل.
وماذا عن الرموز؟
print(hex(ord("😄")))
print(hex(ord("🚀")))0x1f604
0x1f680الأحرف في الأجهزة الرقمية على نوعين:
لعرض الأحرف القابلة للطباعة في محارف آسكي (ASCII)، لدينا المتغير printable من مكتبة string:
import string
string.printable'0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c'كانت أحرف التحكُّم تستخدم لرن جرس الآلة الطابعة ، والتحكم بها ، لكن اليوم الذي يُستخدم منها غالبًا هو الأحرف البيضاء (Whitespace Characters) ويشمل ذلك الأحرف التالية:
\s ويمثل المسافة التي بين الكلمات\t ويمثل المسافة التي بين أعمدة الجداول\n تعليمة سطر جديد\r تعليمة العودة لبداية السطر الجديد\f تعليمة الصفحة الجديدة\v تعليمة العمود الجديد\b تعليمة عودة المؤشر بمقدار حرف واحد للكتابة فوق الحرف السابقأما الثلاثة الأخيرة فقد كانت تستخدم فيما مضى، لكن اليوم المستخدم هو الأربعة الأولى فقط. ويجدر بالذكر أن ملفات نصوص نظام ويندوز تستعمل \r\n للانتقال لسطر جديد بينما تستعمل الأنظمة الأخرى \n فقط.
تذكر أن بايثون تعتمد على space و tab للمسافة البادئة للسطر (indentation)، لتحديد نطاقات القطع البرمجية بحسب المحاذاة العمودية.
import string
string.whitespace' \t\n\r\x0b\x0c'يهمنا هنا الأحرف البيضاء لأنها تظهر في النصوص وقد تكون مزعجة عند معالجتها. لنلقي نظرة على ثلاثة من الأحرف البيضاء: المسافة (space)، التبويب (tab)، وتعليمة السطر الجديد (linefeed).
# Tab character: "\t"
print('A\tB')A B# Space character: " "
print(' A B ') A B # Newline character: '\n'
print('A\nB')A
Bلاحظ أن طول السلسلة النصية هو عدد الأحرف في السلسلة، سواء كانت قابلة للطباعة (printable) أو أحرف بيضاء (whitespace).
assert len('A B') == 3
assert len('A\tB') == 3
assert len('A\nB') == 3لاحظ أن هذا الإجراء سيزيل الأحرف البيضاء من بداية ونهاية السلسلة النصية، ولكن ليس الأحرف البيضاء في منتصف السلسلة
قبل:
text = '\t hello world \n\n\n'
print(text) hello world
بعد:
print(text.strip())hello worldانظر: Splitlines
text = '''
Hello
World
How are you?
'''إذا تركنا القطعة البرمجية كما هي في السطر من غير print فإن ذلك يعرض السلسلة النصية كما هي (بما في ذلك أحرف المسافات البيضاء)
text'\nHello\nWorld\n\nHow are you?\n'أما إذا وضعنا print فإنه يطبع الأحرف المرئية ، وينسِّقُ المظهر بناءً على أحرف التحكُّم المخفية:
print(text)
Hello
World
How are you?
text.splitlines()['', 'Hello', 'World', '', 'How are you?']إذا لم نحدد محدد الفاصل فإن الفاصل الافتراضي هو المسافة.
print("Hello, world".split())['Hello,', 'world']هنا نحدد الفاصل أنه الحرف "l":
print("Hello, world".split("l"))['He', '', 'o, wor', 'd']لإزالة الأحرف البيضاء جميعها؛ نستعمل التكرار هكذا:
text = '\t hello world \n\n\n'
sp = text.split()
print('split:', sp)
clean = ' '.join(sp)
print('clean:', clean)split: ['hello', 'world']
clean: hello worldالفصل في الداخل ينتج قائمة من النصوص، بعضها فارغ لوجود الأحرف البيضاء المتتالية، فلا تتضمن في القائمة الناتجة.
يسمّى الحرف \r بالعودة للبداية لأنه يعني فعل يقوم بإرجاع المؤشر إلى بداية السطر.
كانت آلة الطباعة قديمًا يتحرك رأس الطباعة فيها بعد طباعة كل حرف. ثم عندما ينتهي السطر، يجب على الشخص أن يقوم بعمليتين:
\r)\n)وهما مستخدمان اليوم فيما يُعرض على الشاشة.
ففعل print في الحقيقة يضع سطرًا جديدًا (حرف \n) في الوضع الافتراضي. فإن أردنا ألا يضعه، فنحدد العامل end الذي فيه على النحو التالي:
print('Hello', end='')
print('World', end='')HelloWorldلاحظ أننا جعلنا (end='') أي: لا نريده أن يضع حرفًا بعد طباعة النص. ولذلك ظهرت الكلمتان في نفس السطر.
ولو أردت أن تعيد الكتابة على نفس السطر، يمكنك أن تضع الحرف (\r) الذي يفعل رأس الطباعة بالرجوع لبداية السطر:
print('123', end='\r')
print('45')12345لاحظ أن النتيجة هي طباعة الحرفين 45 فوق الحرفين 12 مع بقاء الحرف الأخير 3 في الأخير. وذلك لرجوع رأس الطباعة.
تستعمل هذه اللطيفة في تحديث العداد حتى يظهر على الشاشة وكأنه يزيد شيئًا فشيئًا. وذلك على النحو التالي (لاحظ أننا نستعمل time.sleep(t) حتى نمثِّل وجود عمليَّة تأخذ وقتًا طويلاً فحسب):
import time
for x in range(10 + 1):
time.sleep(0.20)
print(f'[{x}/10] ' + '===' * x + '>', end='\r')